At Intuit, proud maker of TurboTax and Quickbooks we believe that everyone deserves the opportunity to prosper. We’re dedicated to providing the tools, skills, and insights that empower people around the world to take control of their finances and live the lives they want.
If someone is alerting you to stopped traffic, would you expect them to use the same tone of voice for a fatal accident as for a parade of elephants? Let’s say your sibling leaves a voicemail that “I have to tell you something—Uncle Harold just called.” You’d expect the emotion in their voice to convey some sense of the news, right? As companies push beyond text-based chatbots to enable natural voice interactions, it’s essential to keep in mind that pitch and inflection can be as meaningful as the words themselves.
In my last blog on conversational user interface (CUI) technology, I talked about choosing words that convey the intended sentiment of an interaction. This doesn’t necessarily mean trying to be likeable; it’s more about matching your words to the emotionality of the situation. The same applies to the sound of a voice. Good news should sound like good news, a warning should sound like a warning, and so on. A CUI that always sounds generically cheerful is almost worse than an old-school Stephen Hawking-style synthesizer—in fact, it’s been a staple of dystopian dramas and technology-gone-awry thrillers since HAL was unsettling audiences in 2001: A Space Odyssey.
So – how do you control and tailor the sound of your CUI?
Coding pitch and inflection into your CUI
Just as HTML makes it simple to style text, Speech Synthesis Markup Language (SSML) makes it simple to style the sound of your words. While HTML lets you adjust font size and apply bold, italics, and color, SSML gives you a variety of ways to tweak your tone. For example:
- <emphasis level= “..” > indicates that the enclosed text should be spoken with emphasis
- <prosody pitch = “..” > modifies the baseline pitch, e.g. low / high
- <prosody rate = “..” > changes the speaking rate, e.g. slow / fast
- <prosody volume = “..” > modifies the volume, e.g. soft / loud
- <prosody range = “..” > modifies pitch range (variability), e.g. low / high
- <prosody contour = “..” > sets the actual pitch contour for the contained text (time position, target)
If someone is excited, their prosody (patterns of rhythm and sound) range is high, with a big variation between the highest and lowest pitches in their speech. They’re probably also speaking at a higher volume and more quickly. If they’re sad, they’re likely to speak in monotone, which corresponds to a low prosody range. No matter what emotion we want to convey, there’s a corresponding combination of tags.

One of our earliest experiments, hand-coded with SSML 1.1 tags: “I have something to tell you. Uncle Harold just called. It’s about Martha, you know.”
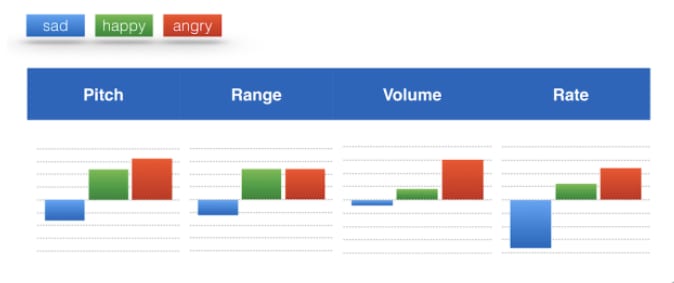
(It’s worth noting that the same kind of process works in reverse. With acoustical analysis tools like Vokaturi, we can infer a customer’s sentiment from the sound of their speech, and use this information to tailor our response accordingly.)
In addition to these standard SSML tags, there are also various proprietary dialects, such as IBM’s Voice Transformation SSML, which includes tags such as:
- <glottal_tension pitch = “..” > indicates tense or lax speech quality, e.g. low / high (low value is perceived as more breathy and generally more pleasant)
- <breathiness level=”..”> sets the perceived level of the aspiration noise (drawing breath), e.g. low / high
You can see that manipulating all these details individually could quickly become overwhelming in practice, so IBM also offers Expressive SSML, which allows you to tag a sentence as simply “good news,” “apology,” “uncertainty,” and so on, with the corresponding underlying styles for each tag applied in the background.
Of course, hand-coding in SSML would be a tedious chore for anyone—especially a content writer. Just as WYSIWYG tools have streamlined HTML layout, Intuit created a graphical tool that makes it easy for people to manipulate and visualize verbal effects. Larger means louder; bold means emphasized; wider means slower; and so on.
Let’s look at a simple example using only the basic SSML 1.1 standard tags. We begin with a plainly spoken, affectless version of the sentence: Miserable is a terrible word you should not use unless you’re stuck suffering in traffic.
We can then mark it up using SSML:
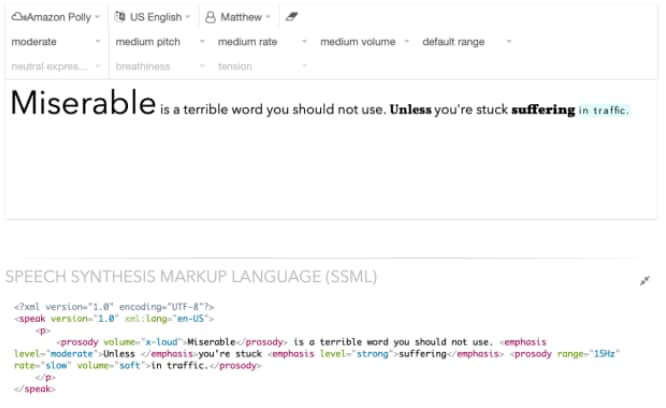
Now, we have a version that sounds much more natural—one where the meaning and sentiment corresponds with the sound.
Toward real conversations
As voice becomes prevalent for customer interaction, some in the industry foresee a need for major brands to develop their own distinctive voice—a differentiated persona or character you could recognize as easily as the Geico gecko, or Dennis Haysbert on the Allstate Insurance ads. (“Are you in good hands?”) Another school of thought anticipates a platform approach in which the CUI is delivered through a device like Alexa or Google Home. In this case, you’d be able to style your speech with SSML, but it would be synthesized using the same universal voice. As with the apps sharing a screen in Microsoft Windows, you’d lose a bit of individuality, but gain accessibility.
There are many decisions still to be made in CUI theory and practice, and many innovations still to come, but the fundamental mission is clear. Intuit is not just looking to deliver a better chatbot. We’re looking to revolutionize the nature of the customer experience by making genuine conversations possible: interactive, audible, and real-time. The CUI literally speaks for our products and our company. It must connect appropriately with our users to encourage appropriate behavior change and reflect our corporate values in relationship with our customers.
“What’s my checking balance?” “About twelve hundred bucks.” “Okay, thanks.” “Don’t forget about the mortgage payment next week—but you’ve got a direct deposit coming Friday so you should be in good shape.” “Right, got it. For now I’m heading to the beach. Can you play some driving music for me?” “Sure thing.”
It’s not as far off as it might seem.
Having shared (sometimes hard!) CUI lessons learned in this blog series, I could stop here, hoping that I’ve inspired you in some small way to build better conversational user interfaces.
But, there’s more. In my fourth installment, I’ll tackle an even more controversial topic: genderless bots.
(In the meantime, if you missed my first two blogs, you’ll find them here: Conversational UI: it’s not what you say, but how you say it and Conversational UI: don’t count on getting a second chance to make a first impression.)