Necessity for change
The road to continuous deployment is not always easy, especially when it involves older systems. Here in the Global Payroll Platform at Intuit UK we began a journey towards continuous deployment.
We started out as a monolith. Payroll is a complex domain and we were working with an aging beast of an application. The system was not always built with the best principles in mind and certains parts showed signs of age and wear. As is often the case with older systems, things were not optimized, processes were slow and things happened in a particular way just because ‘that’s the way we always did it’.
One particular process was our release process. We were releasing each month and it took almost an entire day of engineering time to go through verifying the release, deploying (which would likely fail) and then ensuring each environment was correct. This was a heavily manual process: the verification was manually done, the deployment was manually launched and the deployment itself involved several manual steps. We couldn’t guarantee that each environment was the same. Sometimes something would go wrong and we would have to go back and fix customer data manually or rush to get a hotfix out. Oh and we were using Subversion. This state we will mark as the beginning of journey.
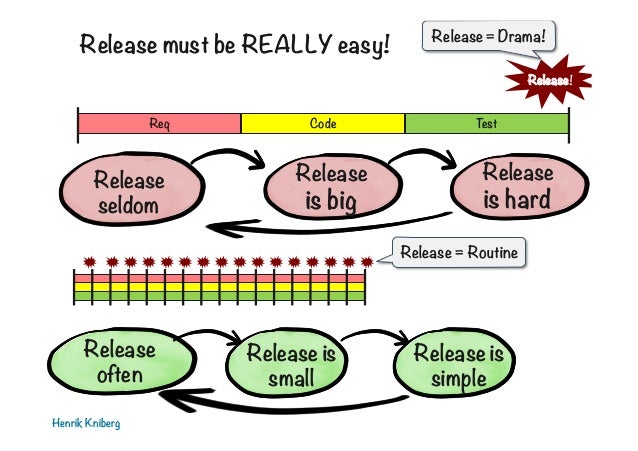
Why did we start on this journey? The team here has a hunger to improve and we were not satisfied with the system that we had. It needed to be better. It was causing pain and we didn’t like pain. We wanted to increase our release cadence to ease our pain. Why do we want to release often? Well, when you release often it generally means releases are smaller. Following Kniberg’s train of thought, the more often we release, the more often we release. It’s a cycle that continuously gathers momentum, each release being easier than the next. We needed to identify our key pain points and solve them, easing ourselves into this cycle first rigidly, forcibly and then smoothly going through the motions as we gathered pace.
“if something is painful do it more often and you will find a way to reduce the pain”.
This should apply to the team’s release process. This is why the cycle is great to be a part of and why it works. We went from monthly releases full of pain to daily releases that happened seamlessly whilst we worked on the things that matter.
Test Coverage and Automation
In order to make changes we needed to be confident in our code. It starts with our application code: we need to be confident that each change can go to production without breaking anything. Having this confidence allows us to deploy without manual testing or verification. At the point where we started our journey our test coverage was not great, around 50%. Better than some projects but nowhere near a level where we could be confident in what we were shipping. We would routinely find problems in production and have to scramble to fix it. We needed to be better.
Improving test coverage and working our way towards a continuous integration process was a key step on the road to continuous delivery. It meant being rigorous about quality. There were mindset changes that had to occur. We had to drive for quality, and we took the principle, “quality is non-negotiable”. We built quality into everything that we do, not just striving for a high code coverage but also making sure we had the right tests in place across all levels. Our coverage was not based just on our application code, but also on the infrastructure code we eventually wrote in service of our automation goals. Everything is tested and ensured to be production ready, from the application to the tooling and infrastructure. At this moment we stand at 90% coverage in our monolith, a far cry from where we once were. We have confidence in our code and that the changes we make have a safety net to ensure that we are not breaking any of the existing functionality.
To get to this we had to tackle pain points in our continuous integration process. We had suffered problems using Subversion as trunk was not always stable. (Actually, it was called trunk2, but that’s a different story.) To facilitate this we migrated from Subversion to Git and now each piece of code is tested in isolation before it can be merged. The migration eased our development process, so that we could adopt a branching and merging strategy that is natural to Git. This eliminates the chance of user error and ensures an always stable master branch (We call it master, not master2 thankfully.) The migration also helped to facilitate a new way of working for the team and we had achieved not only continuous integration, but continuous delivery. [Link – 2] We run millions of tests every week as part of this rigorous quality assurance process. Every piece of code merged to master was guaranteed production ready and could be deployed. We just weren’t doing so.
Trimming the fat
With our new-found confidence in our test coverage it was time to begin automating our release process. The reason to automate was that there was a need to eliminate human error in the process. With manual steps it’s hard to ensure accuracy, unlike with automated steps. We are able to validate that we executing in a specific way and replicate behaviour across environments. Automating each step of the release would allow us to actively spend less time on releases in the future whilst increasing the efficiency and success rate of our release process, a huge benefit.
We identified manual steps that we were doing and needed to automate. For example, we had to execute SQL scripts as part of the release process to modify the database schema. We wanted to improve our release process by cutting people out of it. So we invested some time in looking at solutions for our problem and we settled on using Liquibase [Link – 3] to evolve the database schema and data and execute them automatically as part of our release. This cut out a lengthy manual step of our process. Now some poor guy doesn’t have go through all environments and run a bunch of SQL scripts (which is extremely error prone, I might add). Now the engineer includes the script in a ‘version’ folder and it’s executed during the release. Great!
The change itself wasn’t that huge but the impact was far-reaching. We were no longer manually executing scripts. Our testing mindset meant we wanted everything that we committed and merged to master to be tested, so we also wanted to test these scripts. We included in our build process an execution of the liquibase changesets. This ensured that before any script could be merged into master that it was not going to break the schema.
It was time for us to embark on the next road, one that required a huge mindset change.
Always available
The next problem that we had set out to solve was that in doing a release it meant that the server would be down for the duration of the deployment, which was around 30 minutes. This caused releases to be a pain as they have to be planned around being convenient for our customers. It usually meant at night outside of work hours, and someone would have to stay around to support it. Moving to zero downtime releases would lead us to have more control over when we release. It would give us the freedom to release at any time and know that we would not be breaking anyone.
Implementing zero downtimes releases was not an easy feat. It required a huge change in mindset from the team. We had to get into the habit of thinking about how every change we made could interact with an environment that could simultaneously be working with two versions of the code. We follow the approach of Blue-Green deployments [Link – 4]. This means that at any point we could have two different versions of the application, the current version and the previous version, running at the same time.
Our commitment is to be database compatible with the previous version of the code always. We can’t break every user whilst the new instance is spinning up because we removed a field that we were previously using. It means re-thinking how schema changes work. A change that previously involved just a tweak in the code and a quick script to update the schema now implies several releases and a timed migration.
Getting backwards compatibility as a mindset takes some time. There will be mistakes. So it’s important that we can catch them before they affect a user. We definitely don’t want that to happen. As part of our CI we run the previous and current version of the code with the same database. A series of tests is executed against both instances and, voila! We ensure that when we release to production we won’t break the application for the users that are currently using it.
Backwards compatibility also applies to code changes. We had to explore the topic of feature flags, or feature toggles [Link – 5]. We needed to be able to ship code that wasn’t feature complete and know that we would not break customers. This was another conscious change the team had to make. We had to think about code changes in a backwards compatible way and evaluate where we needed to wrap the changes behind a feature toggle. The result is that anything that is not complete or ready to be consumed is wrapped with a feature toggle so we have peace of mind that all code in the master branch is safe to go to production. This enabled us to start releasing whenever we wanted, and it meant we had the building blocks in place to be able to release more often and ultimately automate our releases.
Onwards to Daily Releases!
The best way to achieve anything, is to break it down into smaller milestones, sometimes referred to as Divide and Conquer [Link – 6]. Our first target was to get to biweekly releases. We had to think about our current process. What could we improve? What were we doing horribly wrong?
We had made some significant changes so far in the process. We had nailed backwards compatibility at the database level, automated our script execution and improved our development process. Master is always stable and sealed with the approval of a barrage of CI tests. This first goal of getting from monthly releases to biweekly releases was our first small step towards continuous deployment. We achieved this along our journey of achieving zero downtime releases, but actually we got through to weekly releases. It had become much much easier to release. The team was identifying pain points and automating where possible. We had entered into the release cycle, where each release makes the next easier. Frequent releases made backwards compatibility changes easier because a chain of several releases becomes several weeks as opposed to several months.
The next target was daily releases. It took further changes in the team mindset and our release and development process to get there. First we looked at our release process which at this point was taking around 5-6 hours. It is not great but it’s better than an entire day, for sure. We had a release sheriff who was appointed every week (they even had a hat, badge and gun). This individual was responsible for creating a release task in JIRA; Identifying the issues included in the release; hitting a button to promote the release candidate; waiting a couple of hours; and then hitting a separate button to release the candidate out. Already it’s obvious some things that we can automate here. Why does the guy have to hit two buttons? He doesn’t, so we made it one button: promote and release.
Next we created a CI bot so that when a PR is merged to master in git it gets tagged with the current release version in JIRA. Great, another manual step gone! This CI bot also does some other awesome things, but that’s a topic for another blog post.
At this point all our sheriff has to do is create the release task in JIRA and then click a button. The process was around 4 hours. A minor improvement but still an improvement. We began looking at the actual Jenkins job that made up the automated release process. There had to be a way to cut down the time from button click to production deployment. Our test execution takes around 45m, the deploy process itself only around 20. There had to be some extra fat we could trim. We identified that we were running tests as part of the master build, taking the candidate and then running the same tests against the candidate to promote it before deploying it to our pre-production instance. After this we would deploy our staging environment, run regression tests against a copy of the production database and finally deploy our production environment.
It’s immediately obvious that there’s some fat there. We run the tests when building the candidate, then we run them again before promoting the candidate. It was unnecessary. So the first thing to do was to just take the candidate that already passed the master build and promote it directly without running any further tests. That’s 45m minutes saved already. Next question is why are we deploying e2e and then kicking off the production release afterwards? This could definitely be done in parallel because we could guarantee that the code was shippable. With some fat trimming we managed to get the button click down to around 1.5 hours. The new process was to take the last green master build, promote it generating a tag in git, deploy it to stage and e2e simultaneously, launch the regression tests against stage and then deploy production. We’re keeping the same quality assurance but saving a lot of time.
As part of these improvements we also automated tagging of versions in JIRA, marking versions as released automatically and sending release notes out to stakeholders automatically once release is finished. It eventually got to the point where clicking the button for a release was cumbersome. So much effort spending those five seconds to open a Jenkins job and build it as opposed to the hours we spent before with manual work. It is amazing how things change. So we now have our release train scheduled to go at 3 every day. No involvement by individuals whatsoever. Releases are just something that happens and thinking in a backwards compatible way is just part of the team’s DNA. We still sometimes click the button for ad-hoc releases when needed. We recently released UK Payroll to general availability here in the UK and in the build-up to the our delivery date we were releasing around 3 or 4 times a day—a huge step forward from where we were.
Looking ahead
Our biggest gain from everything that we have achieved so far on this journey is confidence. We believe in our tools, people and processes. We believe that we can produce code without causing fatal defects in production because we have a battery of automation in place to keep us in check. We have achieved a mindset in the team that enables our success. I opened by stating that getting to continuous deployment is not an easy process, but I would amend that to say that getting to continuous delivery was the hardest part of the journey. It was the culmination of a lot of work from the entire team on our process and a mindset change that has proven itself to be for the better.
We’re at a great point. So what is next? Well, we are aiming for continuous deployment and we’ve still got a ways to go to get there. Having the releases automated and going without individual intervention is a big step in that direction but we still have some processes to define and further pain to solve on how we get to a point where every pull request merged triggers a release.
I hope you’ve enjoyed hearing about our journey towards continuous deployment.
References
[Image – 1] – https://image.slidesharecdn.com/howdoyouknowthatyourproductworkshenrikkniberg-140731012339-phpapp02/95/how-do-you-know-that-your-product-works-henrik-kniberg-colombo-agile-conference-2014-29-638.jpg?cb=1406769878
[Link – 2] – https://continuousdelivery.com/
[Link – 3] – http://www.liquibase.org/
[Link – 4] – https://martinfowler.com/bliki/BlueGreenDeployment.html
[Link – 5] – https://martinfowler.com/articles/feature-toggles.html
[Link – 6] – https://effectivesoftwaredesign.com/2011/06/06/divide-and-conquer-coping-with-complexity/