Authors: Madhavan Narayanan, Amit Jere, Jason Webb, Amit Kaushal, Sankara Rao, Sajith Sebastian, Gokul Sarangapani
Abstract
Asynchronous integration is a key enterprise pattern that enables loosely coupled services. With JMS, loose coupling is enabled by services exchanging messages via a messaging system. Intuit’s Messaging Platform, built on top of RedHat’s ActiveMQ JMS technology, is running in AWS and supports queueing use cases for asynchronous integration between components in the same application and between different services that are deployed in the same or different AWS regions. It is a highly transactional multi-tenant platform, currently used by 2000+ service integrations processing 60+ Billion messages per year at a concurrency of 36K+ messages per second with less than 20 ms TP99 publish response time with 99.999 availability and 100% self-service support for Day 0/1/2 operations. Several tier zero integrations for Intuit flagship products like Quickbooks Online and TurboTax Online are built on top of the platform. While the platform operated out of Intuit’s private data centers (aka IHP) for initial few years since its inception in 2015 and successfully served customer needs, with the migration to AWS in Summer of 2018 and also due to increasing customer traffic a significant degradation in performance and scalability was seen. In this paper, we present the various issues that were observed, the activities/experiments that were done to troubleshoot them, and the solutions implemented thereof to continue to meet the business needs of high availability, performance, and scale for the next 3 years. The “Outcomes” section describes the improvements to the performance and scalability of the Intuit Messaging Platform.
1. Overview
This section lists the significant improvements that were done to the performance and scalability of the Intuit Messaging Platform. The details of how these improvements were achieved are explained from section 2 onwards.
Outcomes
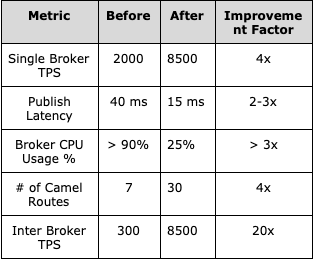
The table given below summarizes the improvements seen in the key metrics of the platform.
2. Intuit Messaging Platform
What is Intuit Messaging Platform?
Intuit Messaging Platform is an enterprise messaging solution that consists of a highly distributed set of ActiveMQ broker instances. ActiveMQ is an open source messaging software developed by Apache Software foundation and supports a fully compliant JMS 1.1 client.
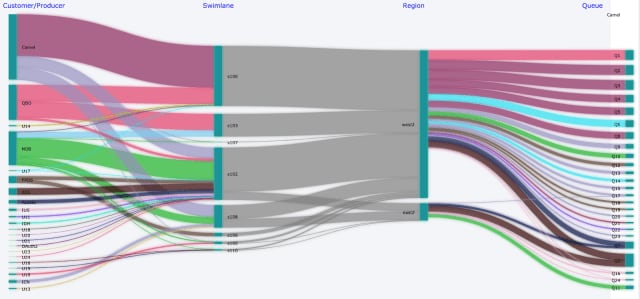
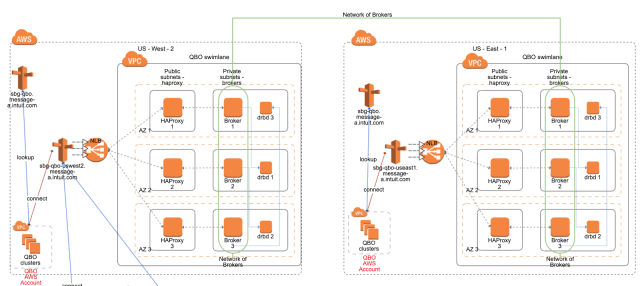
The platform is running in 2 AWS regions (US-WEST-2 and US-EAST-2) that are connected over WAN and other than providing DR, it provides an ability for clients to produce in one region and consume in another region, if required. To ensure high availability within one AWs region, the brokers in a swimlane are distributed across 3 AWS availability zones in one AWS region. Further to avoid noisy neighbor situations and manage the blast radius, the broker instances are grouped into multiple swimlanes, with each swimlane running a set of brokers interconnected using ActiveMQ’s network-of-brokers topology. There are ~10 swimlanes in Intuit Messaging Platform and customers are typically assigned a specific swimlane through an onboarding process and are allowed to produce and consume messages within the swimlane.
While ActiveMQ’s network-of-brokers setup makes it possible for messages to be consumed from any broker within a swimlane, Apache Camel is used to route messages across swimlanes wherever needed. Camel is also used to support custom routing within a broker using header-based filters.
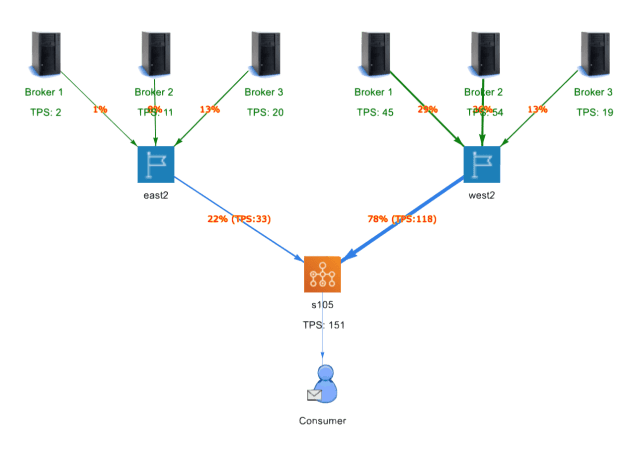
The diagram in Appendix A shows what a swimlane in AWS looks like.
Why Intuit Messaging Platform?
- Intuit Messaging Platform enables loose coupling in distributed transaction processing wherein different components of the system can be designed, evolved, and operated relatively independently of each other.
- With Intuit Messaging Platform, messages can be synchronously stored, asynchronously forwarded/processed and synchronously removed enabling the design of reliable distributed transaction processing solutions
- Offers multiple integration patterns for different client needs
- Simple Point-to-Point Queues
- Topic based Publish/Subscribe
- Virtual Topics for durable consumption by subscribers
- Camel Routing for advanced filtering and routing of messages
- Offers reliable messaging with zero message loss and exactly-once message delivery
- Highly available using a cluster of brokers
- Is accessible using JMS API, an industry standard interface for asynchronous messaging
ActiveMQ
ActiveMQ is an open source, JMS 1.1 compliant, message-oriented middleware (MOM) from the Apache Software Foundation that provides high availability, performance, scalability, and security for enterprise messaging and is widely adopted in the industry
Network of Brokers
To support scalability and high availability, activeMQ allows multiple broker instances to be connected together into a network and enable distributed queues and topics. This network of brokers allows clients to connect to any broker in the network and start consuming messages regardless of the actual location where the messages were produced.
To achieve this, ActiveMQ networks use the concept of store and forward, whereby messages are always stored in the local broker before being forwarded across the network to another broker. This means that if messages can’t be delivered due to connectivity issues when the connection is reestablished, a broker will be able to send any undelivered messages across the network connection to the remote broker
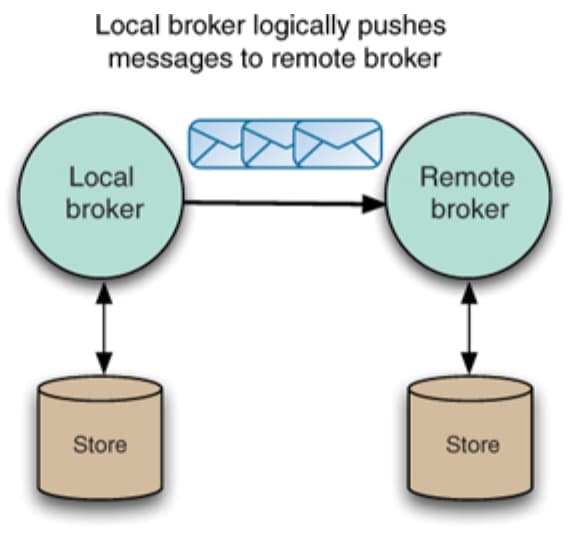
To form a network, ActiveMQ uses a discovery agent to locate remote broker(s) and (re)establish connections. The discovery can be:
- Dynamic – Searches for brokers using multicast or rendezvous
- Static – Configured with list of broker URLs with which to establish a connection
Intuit Messaging Platform currently uses static pre-configured lists to form different swimlanes. To achieve High Availability and also to handle region level outages, the list included connections within brokers in the same region (known as the LAN connections) and connections across the region (WAN connections). Considering the network speed and delays, WAN connections are configured with stricter rules for forwarding messages.
To enable easy access for customers and also to ensure fair distribution of client connections across the brokers in a network, the Intuit Messaging Platform uses a network load balancer that distributes the connection requests in round robin fashion. As the messaging platform is shared by multiple services, the producer connections and consumer connections can land on different brokers.
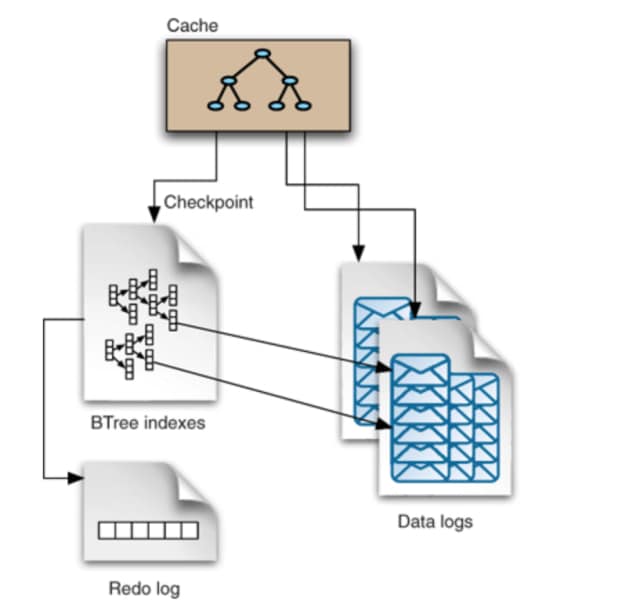
KahaDB Message Store
For reliable message storage and recovery combined with high performance, ActiveMQ supports a file based message store known as ‘KahaDB’ and recommends the same for general purpose messages.
KahaDB is designed to facilitate high-speed message storage and retrieval. The bulk of the data is stored in rolling journal files (data logs), where all broker events are continuously appended. In order to facilitate rapid retrieval of messages from the data logs, a B-tree index is created, which contains pointers to the locations of all the messages embedded in the data log files. The complete B-tree index is stored on disk and part or all of the B-tree index is held in a cache in memory.
Apache Camel Integration
Apache Camel is a versatile open-source integration framework based on known Enterprise Integration Patterns and enables one to define routing and mediation rules in a variety of domain-specific languages. Multiple Apache projects leverage Camel as a routing and mediation engine. ActiveMQ is one of them and enables the use of Camel routes via an embedded plugin.
Intuit Messaging Platform uses ActiveMQ’s Camel integration to provide support for advanced filtering and routing of messages
3. Background
Evolution of Intuit Messaging Platform
Intuit Messaging Platform started its journey as a simple messaging solution for a small set of customers in 2015 and evolved over the next few years into an enterprise messaging platform supporting all of Intuit and thousands of asynchronous queuing integrations.
During the initial phases of its journey, the Intuit Messaging Platform was primarily operated out of Intuit’s private data centers (IHP) by all Intuit services for multiple years before the migration journey to AWS started.
To support customers during the AWS migration journey, the Intuit Messaging Platform was operated in a hybrid mode with brokers running in both IHP servers and AWS EC2 instances.
During this phase, it was observed that there is a significant difference in the performance of the activeMQ brokers running in IHP host vs EC2. While an IHP host with 256GB RAM, 20 cores (40 vCPUs) and 1TB disk store used to support 15K TPS an EC2 with similar configuration lagged by a factor of up to 5x. With a majority of the Intuit Messaging Platform traffic being handled by IHP brokers, this was not a major concern then.
IHP Exit
When it was mandated as an organizational goal to move all Intuit services completely out of IHP by end of 2018, it was decided to run all Intuit Messaging Platform brokers on EC2 instances and discard the hybrid mode. This triggered an exercise within the Messaging team to critically evaluate the broker performance on EC2 instances and find solutions to improve bottlenecks if any.
In the next few sections, we will discuss the various experiments that were done as part of this exercise, the issues found and the solutions that were implemented.
These solutions were rolled out to production in a release named Intuit Messaging Platform 2.1 and have been successfully effective for the past few months. In this paper, we will also provide a detailed comparison of the performance metrics observed before and after Intuit Messaging Platform 2.1
Key Performance Metrics
The following are some of the key messaging metrics that were considered for the performance evaluation and improvement
- Publish Latency
This is the time taken by a messaging client to produce a message to the broker and get acknowledgment. Lesser this value, the better
- Publish throughput
This is a measure of the number of messages that could be produced to a broker within a time period. Typically measured as TPS (message transactions per second). Higher this value, the better
- Consumption throughput
This is a measure of the number of messages that could be delivered to starving consumers within a time period. Typically measured as TPS (message transactions per second). Higher this value, the better
4. Intuit Messaging Platform Performance, Scalability and Operability Improvements
Limitations seen in the platform performance and scalability
The following table captures the performance of some of the key metrics observed with Intuit Messaging Platform 2.0 in AWS when tests were run involving the following commonly used patterns
- Messages were produced to a broker and consumed from a different broker
- Camel routes were used to selectively copy messages to different target queues
Performance Tuning and Scalability Improvement Tracks
In the context of above-mentioned challenges and considering the distributed architecture of Intuit Messaging Platform with its network-of-brokers configuration, the analysis and tuning was done in the following 3 distinct tracks to improve the operability, performance, and scalability of the platform
- Understand and improve the read/write performance for queues and topics in a single broker
- Understand and improve the performance and scalability of network-of-brokers
- Understand and improve the performance and scalability of camel processing
Broker Level Performance
In this track, the team attempted to understand the various factors that affected the read/write performance of queues and virtual topics.
It should be noted that the ActiveMQ brokers on AWS EC2 do incur an additional overhead of encryption/decryption of the message that gets stored in the disk which is not the case with brokers running on IHP hosts.
Notwithstanding the above, Intuit Messaging Platform team wanted to understand if there are other factors in EC2 that influenced the degraded performance.
Disk I/O
One of the main differences between the IHP host and EC2 instance is the use of network-mounted EBS volume in EC2 hosts for the message store. The following tests were done to check if disk I/O is causing the bottleneck.
- EC2 brokers were using EBS volumes with type ‘gp2’ which were provisioned with an IOPS value of 3072. Upgraded to volume type ‘io1’ which allows up to 6000 IPS. However, it made little difference to the Publish throughput.
- Ran standalone tests with ActiveMQ provided DiskBenchmark tool and found that the ‘gp2’ EBS volume was sufficient enough to handle high throughput if writes are batched.
Improving Batched I/O
With the above observation, we browsed through ActiveMQ source code and verified that message write operations by multiple concurrent publisher threads were actually getting batched together for efficient write throughput.
- To verify if this batching is really happening in practice, we ran tests with the ActiveMQ parameter ‘org.apache.kahadb. journal.appender.WRITE_STAT_WINDOW’ set to a non-zero value. This enabled us to monitor the average write batch size.
- In a test running 600 producers writing to 5 different queues (5KB message size, no consumers), it was observed that the average write batch size was low around 20KB
- To understand why the concurrent producer threads were unable to pass the messages to disk writer thread in time for efficient batching, we took multiple dumps of thread stack traces during the test run and analyzed them to find a pattern
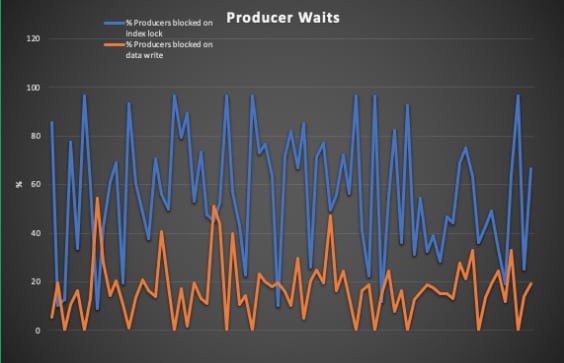
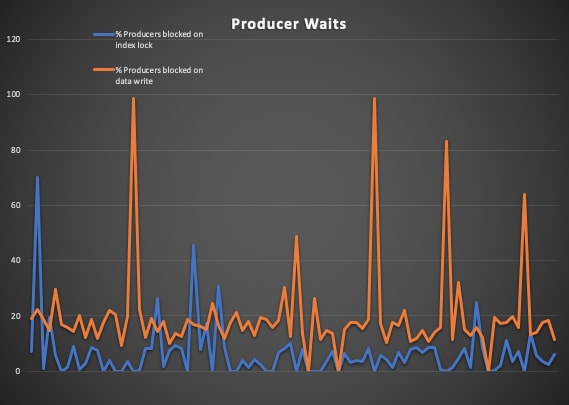
- From the thread stack traces, it was found that in many cases most of the producer threads were blocked in acquiring the lock to update the in-memory index cache maintained by ActiveMQ KahaDB store. The following graph shows how a large number of threads (blue line) are waiting for the index lock than the threads (orange line) that are waiting for a signal from the disk writer thread. The index lock itself was held by a thread that was flushing the index metadata to disk
- With the above happening, the test could only achieve a maximum overall throughput of ~8K TPS as shown below
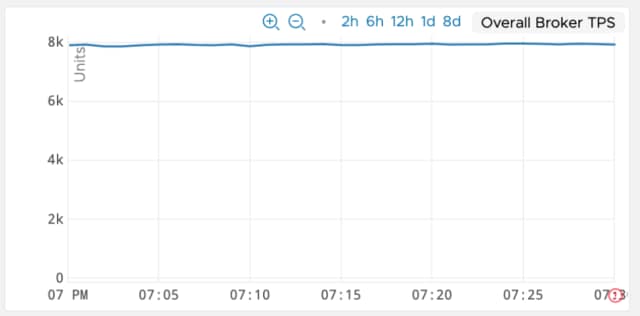
- After understanding how the index metadata and the actual journal of the kahaDB store work together, it was realized that the index was being flushed to disk too often resulting in sub-optimal publish latency and throughput.
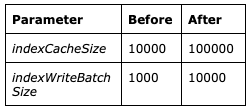
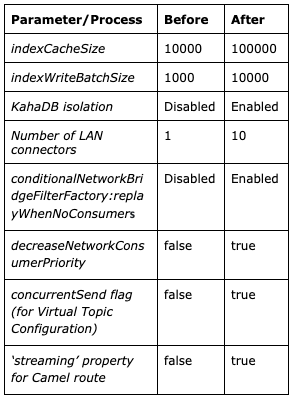
- To solve this, the kahaDB parameter settings indexCacheSize and indexWriteBatchSize were increased
Increasing indexCacheSize reduces the instances of page swaps in and out of memory
Similarly, increasing indexWriteBatchSize increases the number of dirty indexes that are allowed to accumulate before KahaDB writes the cache to the store.
With these new values, it was immediately seen that the number of occurrences of producer threads waiting for index lock reduced drastically, enabling more messages to be passed to the disk writer thread. The average write batch size increased to more than 100 KB
The below graph shows how the pattern of producer thread waits inverted with the new settings
Also, the test was now able to achieve an overall throughput of 11K TPS as shown in the below diagram
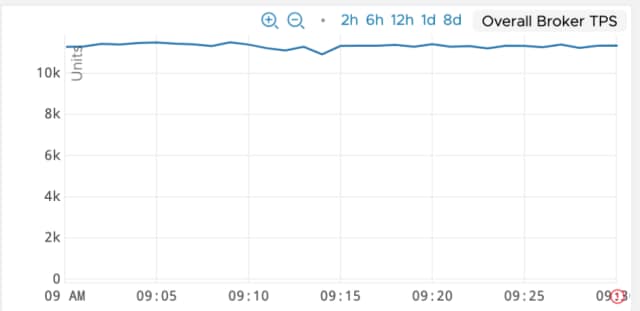
While the above improvement was seen with producer-only tests, similar improvements were seen when running both producers and consumers.
Index segregation with mKaha
Further analysis of the thread stack traces and heap dumps revealed heavy contention between producer and consumer threads to obtain the index lock to record bookkeeping operations.
One possibility to reduce this contention would be to have separate index stores for each of the queues. This way producers and consumers working on a queue would not be blocked by operations on another queue. This segregation is possible using the mKaha (multiple Kaha) configuration in ActiveMQ where in different Kaha stores are configured for different queues
With mKaha usage, we were able to see a big improvement in the overall TPS (both producer and consumer).
Concurrency with Virtual Topics
While the above changes improved the write performance to queues and resulted in lower publish latency and higher publish TPS, there was another issue seen with Virtual Topics.
A message published to a virtual topic gets copied to all the subscriber queues of the topic. It was noticed that the publish latency for the virtual topic is the sum of the latencies incurred for the individual queues. As the number of subscribers increased, the publish latency for the virtual topic became worse.
To solve this, we enabled an activeMQ setting ‘concurrentSend’ that can be applied to Virtual Topic interceptors. ConcurrentSend uses an executor to fanout the sends to subscriber queues in parallel. This allows the journal to batch writes which reduces disk io. After this setting, it was noticed that the publish latencies on virtual topics vastly reduced and were independent of the number of subscribers
Network-of-Brokers Performance
While the performance tuning done at the individual broker instance level helped to improve the publisher performance (latency and throughput), the message consumption throughput was still an issue when consumers and producers are connected to different broker instances. The ‘store and forward’ speed of network-of-brokers were not fast enough to deliver messages to starving consumers. Oftentimes, messages were stuck and growing in the specific broker(s) while consumer connections in a remote broker were only able to consume messages at a speed not exceeding 250-300 TPS.
This resulted in many operational challenges where customers producing messages at high TPS were not able to consume at the same rate if the consumer connections were established with the wrong broker. Intuit Messaging Platform team often had to resort to an operational process known as ‘connection rebalancing’ to ensure the free-flow of messages.
Increasing LAN/WAN Connection Bandwidth
The slowness in inter-broker transfer of messages was mainly due to the use of a single connection (LAN/WAN) between brokers for transferring messages. With message persistence, a single connection was at best able to support only ~300 TPS.
As indicated already, Intuit Messaging Platform uses a static list of connections between brokers to establish the ‘network’. We added support in ActiveMQ configuration to enable dynamic replication of connections. The replication factor could be controlled swimlane-wise.
With this support, we are able to increase the number of LAN/WAN connections between brokers and were able to go well past the 300 TPS limit.
While the increase in LAN connections had a positive impact on the easy and quick flow of messages between brokers, it opened a new set of challenges. The next few sections describe these issues in detail
Stuck messages
While messages can move across the network of brokers to find their way to an external consumer, there are instances when they get stuck at a particular broker. This happens mostly when external consumers re-establish their connections and get connected to a different broker.ActiveMQ, by default, disallows a message from re-visiting a broker that had already seen the message and this results in messages getting stranded at specific brokers after visiting all other brokers. While this was an existing issue, with the increased LAN connections and hence increased inter-broker traffic, we started seeing more of these issues requiring Intuit Messaging Platform team to intervene and manually move the messages to the right brokers where consumers are connected. This became a chronic issue with some customers who had very few consumer connections and kept reconnecting.
To solve this problem we did research on ActiveMQ configuration and code and found an implementation of a network bridge filter known as conditionalNetworkBridgeFilterFactory that allows replay of a message back to an already visited broker if there are no local consumers. This filter can be applied to destination policies by setting attribute ‘replayWhenNoConsumers’ to true as shown below

This can be avoided if Intuit Messaging Platform customers do not use selection filters with their consumer connections and consume all messages (and discard at client side if appropriate). In general, this has always been the recommendation from Intuit Messaging Platform team to customers.However, studying the code of conditionalNetworkBridgeFilterFactory, we found that there is still a remote possibility of messages getting stuck if there are local consumers on the broker but the messages cannot be delivered to the consumer if there are selection filters specified which prevent the delivery.
Reducing unnecessary/redundant LAN traffic
Another undesired side-effect of increased inter-broker connections was a dramatic increase in the traffic between the brokers.
With more LAN connections between brokers and enabling of message replay to already visited brokers, we started seeing that a large number of messages were hopping amongst all the brokers in a swimlane multiple times before finally delivered to an end consumer. It was so severe that there were many instances when the volume of inter-broker traffic was manifolds the actual customer generated traffic.
On analyzing this behavior with reference to the activeMQ configuration that was used, we discovered that the inter-broker consumer connections were treated by ActiveMQ brokers as fast consumers and the messages were readily moved to another broker than a locally connected end consumer.
To fix this, we used an ActiveMQ configuration property ‘decreaseNetworkConsumerPriority` which when set to ‘true’ gives higher priority to local consumers than network consumers. After enabling this property, we saw a huge improvement in the traffic pattern and the inter-broker traffic reduced by great extent.
Camel Routing Performance
With performance improvements achieved both at single broker and swimlane (network-of-brokers) level, then next challenge in Intuit Messaging Platform was to solve the severe performance bottleneck seen with Camel processing
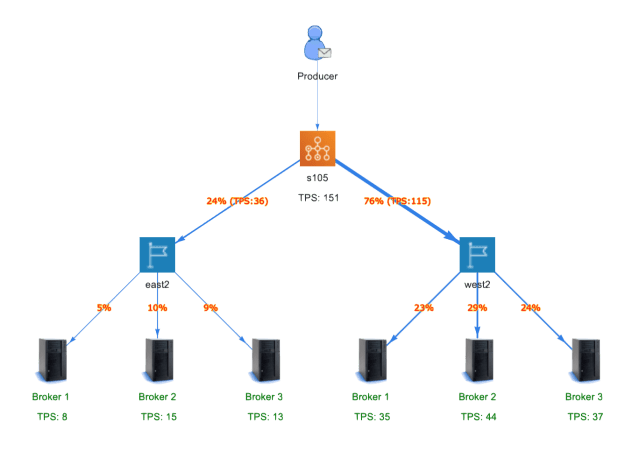
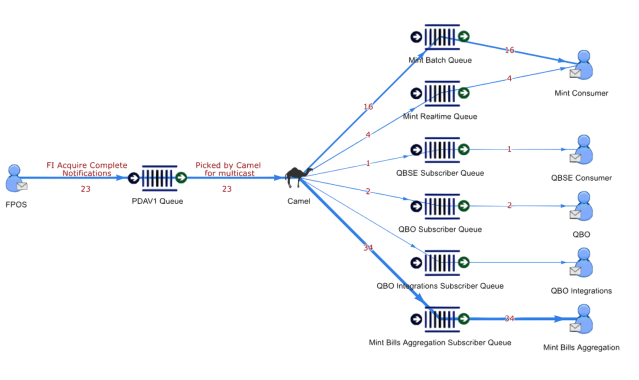
Intuit Messaging Platform uses the embedded Apache Camel plugin in ActiveMQ broker to support advanced routing capabilities for its customers. With Intuit Messaging Platform Camel routes, it is possible for customers to publish messages to a source queue and have the messages routed to multiple different target queues. It is possible to specify different filter conditions for each target queue. This is an advanced feature that is used by some of the top customers of Intuit Messaging Platform
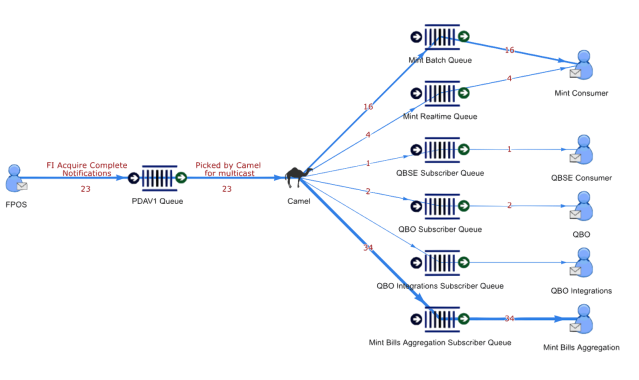
The next section discusses the problem(s) that were seen with Camel routes in Intuit Messaging Platform and how this was solved.
High CPU Usage
It has been observed that when messages were processed by the embedded camel processor in ActiveMQ broker, the CPU usage of the broker host goes high. It was also observed that as the number of target queues increased the CPU usage increased further.
This resulted in some serious limitations and had sometimes also caused outages in Intuit Messaging Platform
- When there is a sudden surge in incoming traffic to the source queue of a camel route, sometimes the CPU usage goes as high as 95% slowing down the entire broker. This results in huge backlogs in multiple queues (source and target queues) affecting downstream use cases. This scenario had happened multiple times in production
- The number of target queues was limited to 7 (an empirical value based on observed CPU usage data). Intuit Messaging Platform team was not able to handle requests for the addition of further routes, much to the disappointment of customers
- Although an advanced and powerful feature that can benefit customers in apt use cases, Intuit Messaging Platform team generally shied away from recommending usage of Camel routes to customers
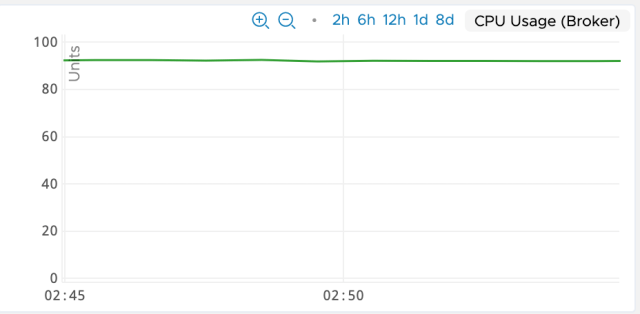
To solve this issue, we used debugging tools/aids such as Java Flight Recorder, memory heap dumps and thread stack traces to deep-dive into the internals of Camel processing and understand the cause for the CPU usage.
After multiple iterations of debug and cross-reference with the source code of Apache Camel, we found that the root cause of the high CPU usage was the use of DelayQueue by Camel’s MultiProcessor logic that attempts to execute tasks writing to target queues in parallel and aggregate in the order the tasks are submitted (in order sequence). The DelayQueue implementation seemed to result in CPU-intensive execution loops.
Since the in-order sequence for target queues is not a requirement for Intuit Messaging Platform, we circumvented the above by using a Camel Route property ‘streaming’ that still executes the tasks in parallel but aggregates in the order they are finished.
Setting the ‘streaming’ property to true resulted in a complete change of the Camel performance. The CPU usage was well within 20% in all the tests and combined with the other improvements discussed in earlier sections, we were able to support as high as 30 target queues with the CPU usage still within acceptable limits
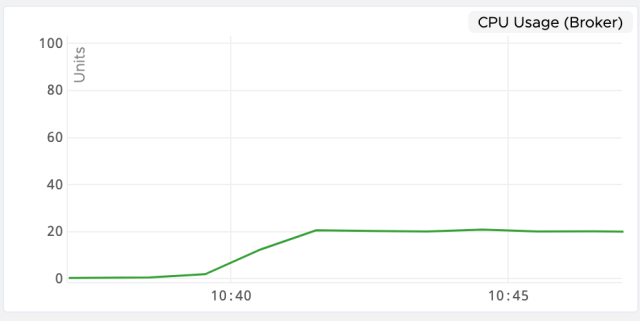
It is also worthy to note that after the above finding and solution, we searched the web for any other reference to similar reported issue and interestingly found an existing JIRA that points to the same issue with use of DelayedQueue in java class SubmitOrderedCompletionService (used when streaming is false)
(CAMEL-11750) Camel route with multicast (parallel) generate huge CPU load
Please refer to the reference section for a link to this JIRA item
5. Summary
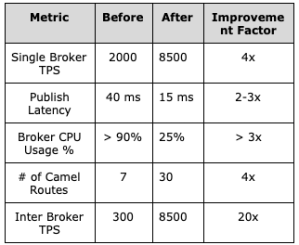
All the efforts spent in understanding and addressing bottlenecks of performance and scalability have yielded impactful results with the messaging platform now handling higher traffic than completely out of AWS and exceeding all the customer SLAs. Below table summarizes the before and after comparison of key metrics.
The following table captures the summary of configuration settings that were tuned to achieve the improvements.
+++++
References/Links
- ActiveMQ Network of Brokers – Documentation
https://activemq.apache.org/networks-of-brokers
- ActiveMQ Virtual Topics – Documentation
https://activemq.apache.org/virtual-destinations
- Camel Issue – JIRA Camel-11750
[jira] [Updated] (CAMEL-11750) Camel route with multicast (parallel) generate huge CPU load
+++++
Appendix A – Intuit Messaging Platform Architecture on AWS
Appendix B – Camel Processing Example
Appendix C – Intuit Messaging Platform Traffic in production