Accuracy is a must when extracting data from financial documents to be used in software. People increasingly prefer to photograph their tax forms, receipts and invoices rather than enter the data on them manually. Automatic information extraction (IE) eliminates manual data entry, as well as the security issues and errors in manual data handling. For sensitive documents containing personally identifiable information (PII), a reliable IE system that does not require a human in the loop is extremely valuable.
Attempts to train machine learning algorithms to do IE are hindered by the lack of high-quality labeled data. Acquiring such data sets requires human-in-the-loop verification and manual field-level redaction (due to the sensitive nature of some fields) and so it is expensive to acquire.
At Intuit, we built a data-driven framework for generating synthetic form images by learning statistical distributions of the real data. This framework has allowed us to generate labeled data sets on the fly and scale up the training set size for supervised machine learning models by several thousand-fold in a matter of hours. We used these synthetic training sets to train an IE model from structured text images. Our framework does not require any human-labeled data, and it performs classification on the images holistically.
IE is a structured prediction problem; and for this class of problem, conditional random fields (CRFs) is the state-of-the-art. CRF belongs to a class of sequence labeling models that have shown good performance over a large number of IE tasks. Under the hood, CRF seeks to locate latent entities in an observed sequence (stream of OCR extracted text in our case) and classifies them into categories, such as the names of people, organizations, monetary values, etc. For tax forms, the form fields are the (named entity) categories.
Synthetic Data Generation Pipeline
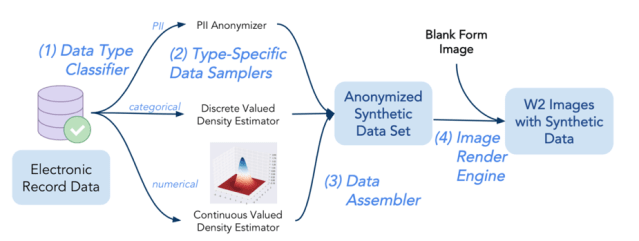 The synthetic data pipeline consists of four main components: (1) the Data Type Classifier, (2) the Data Sampler, (3) the Data Assembler, and (4) the Image Render Engine.
The synthetic data pipeline consists of four main components: (1) the Data Type Classifier, (2) the Data Sampler, (3) the Data Assembler, and (4) the Image Render Engine.
Our synthetic data generation pipeline learns data distributions from Intuit’s electronic W2 records. The Data Type Classifier determines which of the following distributional types each data element falls into: categorical, continuous, and personally identifiable information (PII). The Data Sampler then performs type-specific density estimation and stratified sampling. For PII, we synthesize combinations of data that do not trace back to real identity. Then the Data Sampler performs stratified samplings for all the data elements required for a form image from which the Data Assembler concatenates into a textual document. The output of this step is the synthetic textual data that the Image Render Engine renders over W2 form images.
Named Entity Recognition Conditional Random Fields (NER-CRF)
Our framework for IE consists of:
- Specifying types of named entities. There are two main types of entities for forms: field labels (e.g., SSN) and field values (the value of the SSN). Within each type, there are 32 categories based on the W2 form labels.
- Extracting text from images using an optical character recognition (OCR) and computing features. We use two classes of features: 1) token-based features, which capture words’ morphological patterns, part of speech, and pattern of the current token, and 2) contextual features, for which we use Word2Vec and latent Dirichlet allocation (LDA). Word2Vec learns the statistical relationship of word to their neighbors, while LDA learns distributions of latent topics of the documents over words.
- Training CRF. The extracted features are state parameters in CRF. The model combines the strengths of sequence labeling and classification by learning the probability of content types directly from the observable stream of words, and models the dependencies between observations and types.
Synthetic Data Generator Implementation
Our synthetic data pipeline is packaged in a Docker image stored in an AWS Elastic Container Registry (ECR). It can be launched from any machine with a single script. Our framework is highly parallelizable and is capable of generating millions of form images of synthetic data from a single core machine, which can generate enough data to run large-scale machine learning experiments using complex models.
We use the W2 form synthetic data sets to run a proof of concept, medium-scale and large-scale NER-CRF-based IE with promising synthetic test set performance (> 90% F1). NER-CRF prediction on labeled production images yields slightly lowered performance.
NER-CRF IE Results
We performed a proof of concept (POC) and a medium-scale experiment on the synthetic W2 images using 80/10/10 training/validation/test split. NER-CRF achieves 98.1% F1 in the POC and 94.2% F1 score in the medium-scale experiments over all 64 entity types. We examined NER-CRF performance at the entity type level and found that there are 3 out of 64 entity types for which NER-CRF yields mediocre performance. We are further investigating the reasons for reduced performance for these entities.
The trained NER-CRF is tested on a small set of human curated labeled production images. NER-CRF yields an overall F1 score of 69.0%. The results are summarized in the table below:

We are investigating reasons for the reduced performance, including noisy inputs during OCR failures of production images, noisy labels due to erroneous human-curated labels, and inconsistent OCR text ordering. We are quantifying the contributions from all these possible root causes.
Some Firsts
Our work is the first data-driven synthetic data generator for form images in financial/tax domains with multiple data types including non-traceable PII. These data sets consist of multimodal labels: 1) pixel-level text labels, 2) bounding-box-level form entity labels, and 3) character-level textual ground truths. The ability to generate such data sets with labels on the fly has opened doors to training and evaluating complex machine learning models.
On the modeling side, this work presents the first unique combination of token-based with contextual features as an input to CRF to extract and associate information from tax forms that yields competitive performances to cutting-edge methods.
For more details, please see the full experiment poster.